variable shadowing
init
弊端
- 初始化 error 的处理, 不应该是包自己用 panic 捕获错误终止程序,而是调用来决定是否应该终止程序
- 影响测试, 会在测试之前执行
- 获取执行数据,需要通过全局变量( 全局变量弊端:1. 会被修改,2. 影响测试)
什么时候使用
- 避免错误产生没有err
- 不会产生全局变量
getters and setters
如果只是简单获取值的话,就不应该用
方法命名
- 获取值 Balance 而不是 ( GetBalance)
- 设置值 SetBalance
interface pollution
interface 的价值
- 通用的方法( 如排序)
- 解耦
- 限制实体行为(仅提供特定方法)
只要在当我们真正用到的时候才去创建
we should create an interface when we need it, not when we foresee that we could need it
interface 抽象 是通过发现的,而不是通过创造的
- 生产端接口声明,与实现放在同一个包中
- 消费端接口声明,与使用interface的放在同一个包中
Interface 是通过发现的,符合使用者的需求(与其他语言最大区别就是 Interface 为隐式实现)所以大部分接口应该是是消费端接口声明。
准备库定义生产端声明,可以提供自定义接口的能力。 生产端接口要尽量简洁。
return interfaceBe conservative in what you do, be liberal in fr
Be conservative in what you do, be liberal in what you accept from others.
对自己依赖别人的功能保守,对自己赋予别人的能力保持开放
- 尽量接收 interface
- 尽量返回 结构体
正常 consumer 定义接口, 就会造成循环引用
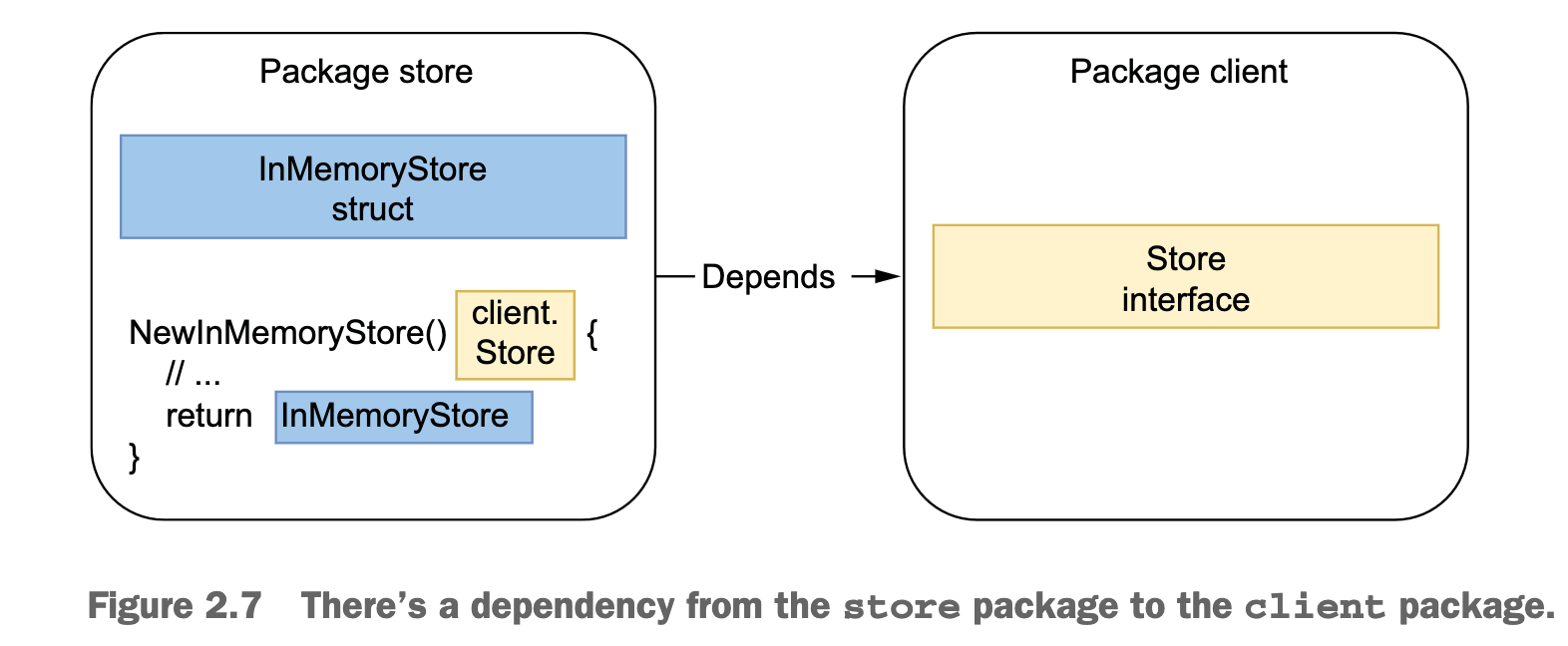
如果 是现房new 的时候返回 interface 就会变成,由实现方来限制了限制了客户端使用接口消费的抽象组合方式
Confuse Generics
限制 constraint, 可以是一下两种
- 接口
- 任意类型
~int, 限制 底层类型
embbding
错误使用将底层的方法公开出来
type client struct { sync.Mutex // 错误地将 Lock() 和 Unlock() 方法暴露给客户端了 protectData map[string]string }
Functional Options Parttern
定义闭包声明函数,更新和修改配置, 有几个好处
- 使用默认配置时, 避免声明空的 cfg 参数结构体
- 通过闭包延迟 err 的处理, 聚合在客户端内部
| |
12 Project Organization
We should minimize what should be exported as much as possible to reduce the coupling between pack-
ages and keep unnecessary exported elements hidden.
包的成员,非必要不公开。
13 Utility Package
创建类似与 common , utility, base, shared 等没有意义的包名,共享一些工具类代码。
14 Ignoring Package name collisions
避免包名和变量名冲突
- 使用不同的变量名
redisClient - 对引用的包取别名
redisPkg
15 Missing code documentation
- exported 的公开变量 都需要进行文档备注
Deprecated: //- Package 的说明应该在
doc.go文件// Package 包名开头 - 与 Go 代码声明有空行间隔 会被忽略
16 Not using linters
17 Creating confusion with octal literal
错误使用 010, 表示八进制
- 0b 二进制
- 0x 十六进制
- 0i 虚数
18 Integer Overflow
整形溢出, 多注意
19 floating points
20 slice length and capactity
the slice length is the number of available elements in the slice,
whereas the slice capacity is the number of elements in the backing arra
长度是 slice 可用的长度, 容量是slice底层数据的长度
22 slice empty and nil
slice nil
- 不需要分配内存, nil slice 是 empty slice
empty slice
- 长度等于 0
23 check slice by nil
通过 list == nil 判断 slice 是否为空,是错误的
要通过长度判断 len(list)判断 slice 是否为空。
24 copy slice
赋值数量为最小两个slice 之间最小长度
复制之前应该,注意复制的目标数组的长度
src := []int{0, 1, 2} dst := make([]int, len(src)) copy(dst, src) fmt.Println(dst)
不同的复制方式
src := []int{0, 1, 2} dst := append([]int(nil), src…)
25 切片更新添加数据副作用
s1 := []int{1,2,3} s2 := s1[1:2] s3 := append(s2, 10}
// Output: // s1 [1, 2, 10]
26 slice 导致内存泄露
使用切变承接输入的大数据数组, 获取小部分数据。
小数据的slice, 仍然会指向大数组的空间,内存占用仍会较高。
需要重新声明 slice, 使用copy 复制需要的数据。
GC 不会回收 slice 已经分配但没有使用的空间。
27 Map 初始化
load factor
overflowed
make(map, hint_size) 初始化 map, 带预计大小, 可以避免map 在插入的时候, 需要复制.
- 获取足够的内存
- 重新平衡分配元素到各个bucket
28 map memory leaks
A map can only grow and have more buckets; it never shrinks.
GC 可以回收 map 的元素, 但是无法回收 map 本身占用的空间大小.
解决方法
- 创建副本, 创建一个新的map, 复制现有的值, 释放原有的map
- map的value 存放 指针, 缩小每一个空的bucket 占用的空间大小 (指针空间 8bytes or 4bytes)
29 值比较
Booleans—Compare whether two Booleans are equal.
Numerics (int, float, and complex types)—Compare whether two numerics are equal.
Strings—Compare whether two strings are equal.
Channels—Compare whether two channels were created by the same call to
make or if both are nil.
Interfaces—Compare whether two interfaces have identical dynamic types and
equal dynamic values or if both are nil.
Pointers—Compare whether two pointers point to the same value in memory or
if both are nil.
Structs and arrays—Compare whether they are composed of similar types.
对比方法
- 简单通过
==对比, 无法处理复杂类型 reflect.DeepEuqal有性能瓶颈- 自己实现对比方法, 参考已经有标准库, 如
bytes.Compare
30 copy value in range
在 range 遍历的过程中, 是值复制
31 range expresion evaluated
for i, v := range exp
exp 针对不同类型表达式, 会在 开始执行 loop 之前, 对exp 进行复制
slice
range 会在开始range的时候, 计算slice 的长度和容量, 并创建一个临时的 slice
![[Pasted image 20230221093451.png]]
| |
会无限执行下去, 因为 len 是每次执行的时候都会计算一次
channel
与slice 一样, 同样会在开始的时候为 channel 创建一个临时变量.
| |
这个在range 这替换的动作是无效的, range 的仍然是ch1
array
| |
会对 a 整个数据进行复制, 输出是2, 原数组不变
修改原数组方案
- 使用 index , 访问和修改数据
- 对数据取指针方法
for i, v := range &a
32 range 过程中使用 遍历元素的指针
| |
&customer 指向的是 range 复制出来的内存
33 对 map 数据的错误消费
- 依赖 map 的顺序, map 的数据是无序的
- 在遍历过程中继续插入新的数据, 结果是不可预测的。有可能会被遍历到,也有可能会被跳过
34 break 层的错误理解
break 对 for, select, switch 三个语句的最内层生效
| |
没有中断, 结果正常遍历。
可以使用 Label 达到中断 for 的方式, 标准库也经常采用该种写法。
35 在 for 中使用 defer
36 没有理解 rune
string 是一个结构体, 有两个字段
- A pointer to an immutable byte sequence
- 长度
Unicode 是字符集 Utf-8 是编码方式
Rune 是 Unicode 的字符集表示,相当于一个字符, golang 使用utf-8编码方式, 所以一个rune 是1-4个字节 bytes.
| |
len()函数返回的是 bytes 的长度
37 对 string 的错误遍历
获取字符串的字符个数 utf8.RuneCountInString
获取字符串的第i个字符
- 如果是纯ascii码字符串,直接通过str[i]获取。 获取出来的是 bytes 编码需要转成字符
- 如果存在非ascii 字符
- 通过
for i, c := range str遍历获取到第 i 个 rune 字符, 和 c 字符编码 - 通过索引获取, 需要先强制转化成
[]rune(str)[i]可以直接获取字符串的第 i 个 rune 字符
- 通过
38 对 TrimRight / TrimSuffix 混淆
strings.TrimRight 是从右到开始移除所有符合的字符集,直到遇到第一个不符合的字符 TrimSuffix 是移除整个字符串
39 使用 += 字符串拼接
使用 += 拼接一系列字符串,会造成内存分配频繁,因为每一个字串都是不变的。
推荐使用 strings.Builder
40 冗余转化成字符串
所有的字符串操作 strings 包, 在 bytes 包都会有相对应的替换方法,没有必要将 bytes 转化成 string 在进行操作。
41 subString 导致内存泄露
substring 生成的 新字符串与旧字符串指向同一块内存,原理同slice
42 方法值接受者和指针接收者
pointer receiver
- 需要修改对象数据
- 接收者包含不能copy的对象,如 sync
- 接收者为大对象
value receiver
- 不修改接收者
- 接收者为 map, channel
- 接收者为小对象, 基础类型
43 命名的返回参数
用处
- 增加代码可读性, 如果无法增加可读性,就不需要命名
- 提前初始化变量
- 使用 naked return 的提前是函数短小,太长的函数会降低可读性,需要一直记住变量
- 不应改混着使用 naked return 和 带参数return
44 返回了未赋值的命名 err
| |
45 interface 返回 non-nil
| |
nil 的结构体, 在返回 interface 的函数之后就永远不等于 nil ![[Pasted image 20230309221827.png]]
解决方案,永远明确地返回 nil
| |
46 不用使用文件名作为参数
使用 io.Reader 做为参数, 替代文件有两种好处
- 方法的具体实现可以与数据源的类型无关, 文件, 或者http, 或者sock
- 方便测试, 无法因为测试而创建一堆文件
47 defer 参数的计算
defer 在代码执行到的时候会, 立刻使用当前函数的参数的变量值, 包括方法的接收者作为参数.
48 panic
什么时候应该panic
- a pure programmer error ( 程序员编码错误 )
- 依赖初始化失败
49 Error Wrap
什么时候使用 Error Wrap
- 添加额外的信息
- 标记为某一特定的错误类型
处理的信息的多种选择
- 直接返回错误
- 自定义错误类型
- fmt.Errorf + %w wrap 错误
- fmt.Errorf + %v 包含错误文字
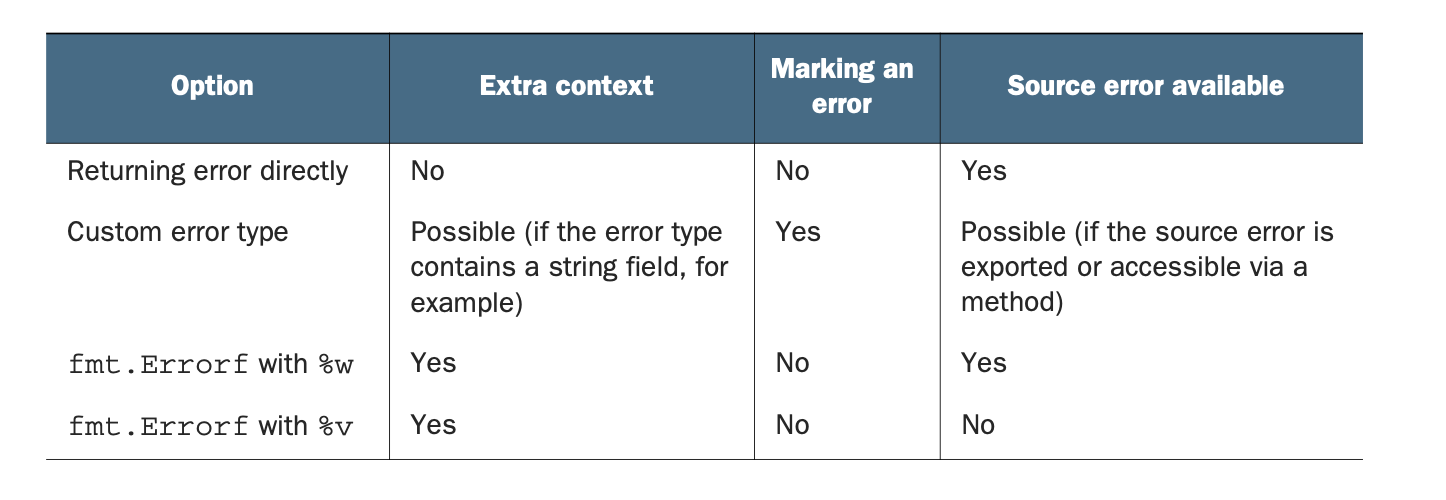
50 用 as 检查Err类型
通过 wrap 的 error 需要使用 error.As(err, &targetErrorStruct{}) 判断是否为目标结构体
51 erros.Is
制定 error 错误信息的原则:
- 可以预测的错误使用制定错误变量
ErrFoo = errors.New("foo") - 无法预测的错误,使用指定错误类型
type BarError struct
使用 error.Is(err, sql.ErrNoRows) 判断错误是否为指定的错误类型.
52 多次处理同一个错误
一个错误多次重复打日志, 会让调试更加艰难.
打印错误也是一种错误的处理方式. 所有, 要么选择打印错误, 要么选择向上抛出错误. 不要两者同时.
向上层函数抛出错误的时候, 需要通过 WrapErr 附加上当前的额外错误信息
53 明确忽略的 error
使用 _ 接收返回的error, 明确表示不处理, 错误
| |
建议再加上注释说明为什么不处理函数错误
54 处理 defer 函数返回的错误
记得要处理 defer 的函数返回的错误, 至少需要显示忽略
55 并发和并行
并发的重点是可以处理多项事务的设计结构, 并行是多项事务可以同时进行处理.
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once. —Rob Pike
并发并不代表多件事务真正意义上的"同时进行", 同时进行是并行, 并发主要处理阻塞的流程 优化
56 并发 不一定更快
过小的切分任务, 会让时间消耗在创建和消费协程上, 并没有真正的提高"并行"能力.
57 通道和互斥锁
通道的底层也是互斥锁.
当协程之间需要传递信息, 或者数据, 使用通道 – 互斥锁的更高抽象
58 数据竞争(data race) 和条件竞争(race condition)
数据竞争:
同时有多个协程同时访问统一块内存, 且至少有一个协程正在写入数据
条件竞争:
事件发生的先后顺序不可控制, 无法控制协程的执行先后顺序, 导致结果不可控.
59 区分任务类型 (计算密集或者 I/O密集型)
如果是计算密集型, goroutine 的并发上线应该采用 runtime.GOMAXPROCS(0)
过多的协程, 可能导致创建过得的 M, 就会出现多个 M 在一个 cpu 核心 中疯狂切换.
60 Conetxt
- Deadline 设置超时时间
context.WithTimeout - 传递取消消息
context.WithCancel - 传递值
context.WithValue context.Err会返回解释, 为何context.Done关闭
传递值时, key 不直接使用 string 是为了避免, 冲突覆盖.
The provided key must be comparable and should not be of type string or any other built-in type to avoid collisions between packages using context. Users of WithValue should define their own types for keys. To avoid allocating when assigning to an interface{}, context keys often have concrete type struct{}. Alternatively, exported context key variables’ static type should be a pointer or interface.
疑惑的时候就使用 context.TODO
When in doubt about which context to use, we should use context.TODO() instead of passing an empty context with context.Background.
61 传递 context
62 关心 goroutine 什么时候停止
关心 goroutine 持有的文件描述符是否被正确的关闭 注意协程持有的资源
63 注意 goroutine 获取循环变量
64 select 是随机, case 先后顺序不保证优先级.
65 消息型 channel
消息型 channel 的数据结构应该使用 make(chan struct{}) 空结构体, 编程惯例, 提醒
接收者, 传递的消息是没有任何意义的.
66 使用 nil channel
在使用 select 的时候, 当 channel 已经 close 掉后, 就可以将channel 设置成 nil ,
让该 case 条件进入堵塞状态
67 分清 buffed and unbeffed channel 的使用场景
68 string format 的副作用
如果有协程正在更新 ctx, context的值的话, 就会出现数据竞争, fmt 读取ctx的内部值
ctxKey := fmt.Sprintf("%v", ctx)
fmt 会读取 string() 的方法, 应注意该方法中的读写锁是否会造成死锁.
69 append 的数据竞争
slice 更新和读取不通的index时不会出问题.
map 操作时存在更新, 无论key是否相同有可能产生冲突. 因为, map 的底层是数组, 不同的 key 也有可能指向相同的数组
70
71 wg.Add 在协程开启前
72 sycn.cond
73 errgroup
74 sync 包不能被复制, 要小心值复制
75 time.Duration 的时间单位是 纳秒
标准使用
| |
76 time.Afte 导致内存泄露
方法内部实现的协程, 需要等到时间到了, 才会释放资源, 所以不要在循环中调用.
77 结构体 序列化和反序列化
结构体嵌套
直接嵌入未命名的结构体, 可能会使用sub embedding struct 的序列化接口方法, 导致bug
| |
a 结构体再序列化的时候会使用 time.Time 的MarshalJSON()的方法
- 使用命名结构体接入
- 重新实现接口方法
time 的对比
time 内部包含 wall clock 和 montonic clock 字段, 返回序列化后的 time 对象, 不包含 montonic clock 直接对比, 会不相同
The general rule is that the wall clock is for telling time and the monotonic clock is for measuring time.
- 可以使用
time.Equal方法 - 或者使用
Truncate移除 monotonic clock 数值
map
map[string]any 数值反序列化后类型都为 float64
78 SQL 错误
sql.Open
sql.Open() 不一定是与数据库服务建立了连接, 具体还是需要看 驱动 实现, 可以通过
ping 方法, 强制建立连接
sql 连接池的配置
sql 连接状态分两种
- 使用者
- idle 等待使用, 已创建但没有再使用
sql 连接池配置
- SetMaxOpenConns 最大连接数量, 考虑到下游服务的性能
- SetMaxIdleConn 在并发高时适当增加, 避免创建耗时
- SetConnMaxIdleTime 并发增加之后, 维持多久销毁连接
- SetConnMaxLifetime 不希望一个连接持续过久
sql.prepared 语句
- 高效: 更加高效, 避免 SQL 重复编译
- 安全: 避免SQL注入
string 处理 null 值
- 使用指针声明
*string - 使用
sql.NullString类型
rows.Err 错误捕获
79 资源关闭
实现 io.Closer 的临时资源需要 及时 close
- http 请求的客户端, respBody 需要close
- sql.Rows
- os.File
80 http handle 忘记 return
81 使用 默认http client 和 server
client
http 的请求步骤
- dial
- tls 握手
- send
- read header
- read body

4个超时配置
net.Dialer.Timeout建立连接超时http.Transport.TLSHandshakeTimeoutTLS 握手超时http.Transport.ResponseHeaderTimeout等待服务返回头此时http.Client.Timeout这个请求的时间限制, from 上述步骤1到5
net/http: request canceled (Client.Timeout exceeded while awaiting headers) 报错
服务端返回超时, 在step4, 读取头时等待超时.
http 连接池
http.Transport.IdleConnTimeouthttp.Transport.MaxIdleConnshttp.Transport.MaxIdleConnsPerHost默认为2, 严重影响并发
server
| |
服务端步骤
- 等待请求
- TLS
- read request headers
- read request body
- write response
3个 timeout
http.Sever.ReadHeadersTimeouthttp.Server.ReadTimeouthttp.TimeoutHandlerhttp.Server.IdleTimeoutkeep-alive 请求可以保持多久
TimeoutHanlder 包裹 handle 当处理超时时,返回503

如果都没有配置超时的话, 服务器就没有超时机制, 会一直等待客户端主动关闭连接. 当服务暴露给不信任客户端时, 至少需要配置 ReadTimeout 和 TimeoutHandler 避免资源被耗尽.
82 对单元测试进行分类
避免执行不需要单元测试, 提升测试效率.
- 使用 tag
go test --tags=integration -v . - 根据环境变量, 使用
testing.Skip()显示调用为什么跳过测试 - 使用
testing.Short()判断当前执行模式, 跳过需要长时间耗时的测试go test -short -v .
83 测试启用 –race
编译时带 --race 会增加程序消耗
- 内存提高5-10倍
- 运行时间2-20倍
避免在生产环境使用, 在CI的时候使用
84 test 的执行模式
parallel
testing.T.Parallel() 会先暂停, 等待顺序测试任务完成后, 继续执行.
go test - parallel 16 . 并发执行测试
shuffle
go test -shuffle=on -v . 打乱 go test 函数的执行顺序
85 Table-driven 表驱动测试
t.Run(name, func(t *testing.T) {})
执行子测试
go test -run=TestFoo/subtest_1 -v
86 避免测试中的 sleep
在并发场景下, 我们使用 time.Sleep 模拟, 任务处理耗时, 但是我们不知道时间是否足够
- 使用多次尝试校验, retry
- mock 对象使用消息通知校验
87 处理依赖时间测试
- 改变依赖, 造假数据
- 修改方法, 让接口传入时间
88 单测工具包
http 相关
- httptest.NewServer
- httptest.NewRequest
iotest
89 正确使用 benchmark 测试
- 忽略耗时函数
- 忽略对硬件底层
90 单元测试的拓展功能
- TestMain
- 从不同的包测试 ( 重视包对外的开放功能)
- cover 单测覆盖率
91 CPU cache
cpu 三级缓存

- cpu cache Line 加载的 locality of reference, 局部性和相关性
- cache line 一般 64 bytes,
CPU 内存加载预测
- Unit stride
- Constant stride
- Non-Unit stride
92 通过 padding 避免并发操作相同内存复制到不同cpu core 中
cpu 会有cache line 加载数据, 如果两个协程, 并发操作的不同的数据字段(在同一块cache line 大小内存中) 内存中. 这块内存会被同时加载到不同的cpu 核心的缓存中. 因为cpu MESI保证内存一致, 一边更新另一边会失效.
When a cache line is shared across multiple cores and at least one goroutine is a writer, the entire cache line is invalidated.
使用 pading , 将同时操作的内存分到不同cache line 中
| |
93 考虑指令集优化
94 内存对齐
内存对齐可以减少结构体占用的内存大小.
结构体的内存对齐系数, 为各字段中最大的系数
95 stack && heap
栈内存是不需要GC, 只是会根据栈的大小范围表示为不可用, 再次使用的时候, 新值直接覆盖旧值.
当变量内存分配到栈上, 且函数退出, 变量引用表示不可用 – 无法再次访问, 所以需要 堆.
堆的使用成本更大, 需要GC, 内存分配成本也更大.
96 优化内存分配
- string.Builder 代替 +
- 避免 []byte 转 string
- slice map 的初始化
- 结构体内存对齐
- 改变 interface 声明, 避免内存逃逸
- sync.Pool
- 编译器优化, 避免 bytes-to-string 转化
97 编译器函数内联
inline. 当调用的子函数较为简单时, 编译器会是将调用函数的内部实现嵌入当前调用点.
- 避免函数的调用成本
- 可以使编译器进一步优化 (比如, 内存逃逸 直接分配到栈中)
当子函数过为复杂时, 可以抽出子函数的复杂部分为另一个调用函数实现 mid inline. 让中间函数嵌入调用点.
98 使用分析工具
- pprof
- trace
99 GC
marks and sweep
- 遍历所有对象, 标记是否在使用
- 遍历所以对象, 清除没有在使用的对象
GOGC 配置 GC 的敏感度, 当 GOGC=100 时, 当堆内存容量涨100%时触发GC.
100 Docker 和 K8s 资源分配对并发性能的影响
引用 http://github.com/uber-go/automaxprocs 自动设置 GOPROMAX